Coral technology
Advanced neural network processing for
low-power devices

Coral is a hardware and software platform for building intelligent devices with fast neural network inferencing.
At the heart of our devices is the Coral Edge TPU coprocessor. This is a small ASIC built by Google that's specially-designed to execute state-of-the-art neural networks at high speed, with a low power cost.
Jump to a section:
Performance
The Edge TPU is capable of performing 4 trillion operations (tera-operations) per second (TOPS), using 0.5 watts for each TOPS (2 TOPS per watt).
The following chart compares the inference time for several popular vision models in TensorFlow Lite format, when executed either on a modern embedded CPU or on the Coral Dev Board (lower is better).

For more numbers like the ones above, see our benchmarks page.
As a part of Google Research, our team is working with other machine learning teams to help build the next generation of neural networks for low-power devices. We're constantly making progress to optimize models for embedded devices, and designing new neural network architectures that are specially-designed to provide fast inferencing speeds in a small package.
For example, the new EfficientNet-EdgeTPU model provides new levels of performance that balance low latency with high accuracy on the Edge TPU. It comes in three sizes (small, medium, and large), offering increasing levels of accuracy with trade-offs in inference latency.

Reliability
The following table shows measurements for the life of the Edge TPU, as failures in time (FIT). The different junction temperatures (Tj) are used to calculate the reliability based on test data collected during part qualification. These figures are valid only when the system provides thermal management that maintains Tj below the maximum limit.
| Tj | FIT |
|---|---|
| 85 °C | 74 |
| 70 °C | 27 |
| 55 °C | 9 |
Note: These measurements are for the Edge TPU ASIC only. Complete device reliability will vary across products, and is provided in the individual product datasheets, if available.
Flexibility and scalability
We offer the Edge TPU in multiple form factors to suit various prototyping and production environments—from embedded systems deployed in the field, to network systems operating on-premise.
For example, our USB Accelerator simply plugs into a desktop, laptop, or embedded system such as a Raspberry Pi so you can quickly prototype your application. From there, you can scale to production systems by adding our Mini PCIe or M.2 Accelerator to your hardware system.
If you're looking for a fully-integrated system, you can get started with our Dev Board—a single-board computer based on NXP's i.MX 8M system-on-chip. Then you can scale to production by connecting our System-on-Module (included on the Dev Board) to your own baseboard.
For smaller and more power-constrained hardware applications, we also offer the Dev Board Micro, a microcontoller board with an integrated camera, microphone, and Edge TPU. It includes a dual-core MCU (Cortex M7 and M4 cores), allowing you to build applications that run tiny, low-power ML models on either MCU core with TensorFlow Lite for Microcontrollers and then cascade to larger models with acceleration on the Edge TPU.

Model compatibility
The Edge TPU supports a variety of model architectures built with TensorFlow, including models built with Keras.
The workflow to create a model for the Edge TPU is based on TensorFlow Lite. No additional APIs are required to build or run your model. You only need a small runtime package, which delegates the execution of your model to the Edge TPU.
To build a compatible model, you need to convert a trained model into the TensorFlow Lite format and quantize all parameter data (you can use either quantization-aware training or full integer post-training quantization). Then pass the model to our Edge TPU Compiler and it's ready to execute using the TensorFlow Lite API.
Read more about how to create a model for the Edge TPU.
Pre-compiled models
We have verified many popular model architectures for image classification, object detection, semantic segmentation, pose estimation, keyphrase detection, and more to come.
If you want to try your application using one of these models, you can download a pre-trained version of our models.
Mendel Linux
To ease development with our fully-integrated systems (the Dev Board, Dev Board Mini, and System-on-Module), we created an open-source derivative of Debian Linux called Mendel.
We've optimized Mendel for embedded systems by making it very lightweight. So although you can connect a keyboard and monitor to get a shell interface, you won't find any desktop apps. What you will find is a familiar Linux interface and a Debian packaging system, providing access the extensive Debian software archives and a huge range of customizations.
Mendel also comes bundled with the tools you need to build your headless ML applications, including standard Python and C++ libraries, the Edge TPU runtime, and extra API libraries to simplify your app development (PyCoral for Python apps and libcoral for C++ apps). Additionally, we include a tool called MDT (Mendel Development Tool) that makes it easy to connect securely (using SSH/mDNS), transfer files, and run other commands from a remote computer.
The following illustration provides a basic overview of the Mendel system and software stack.
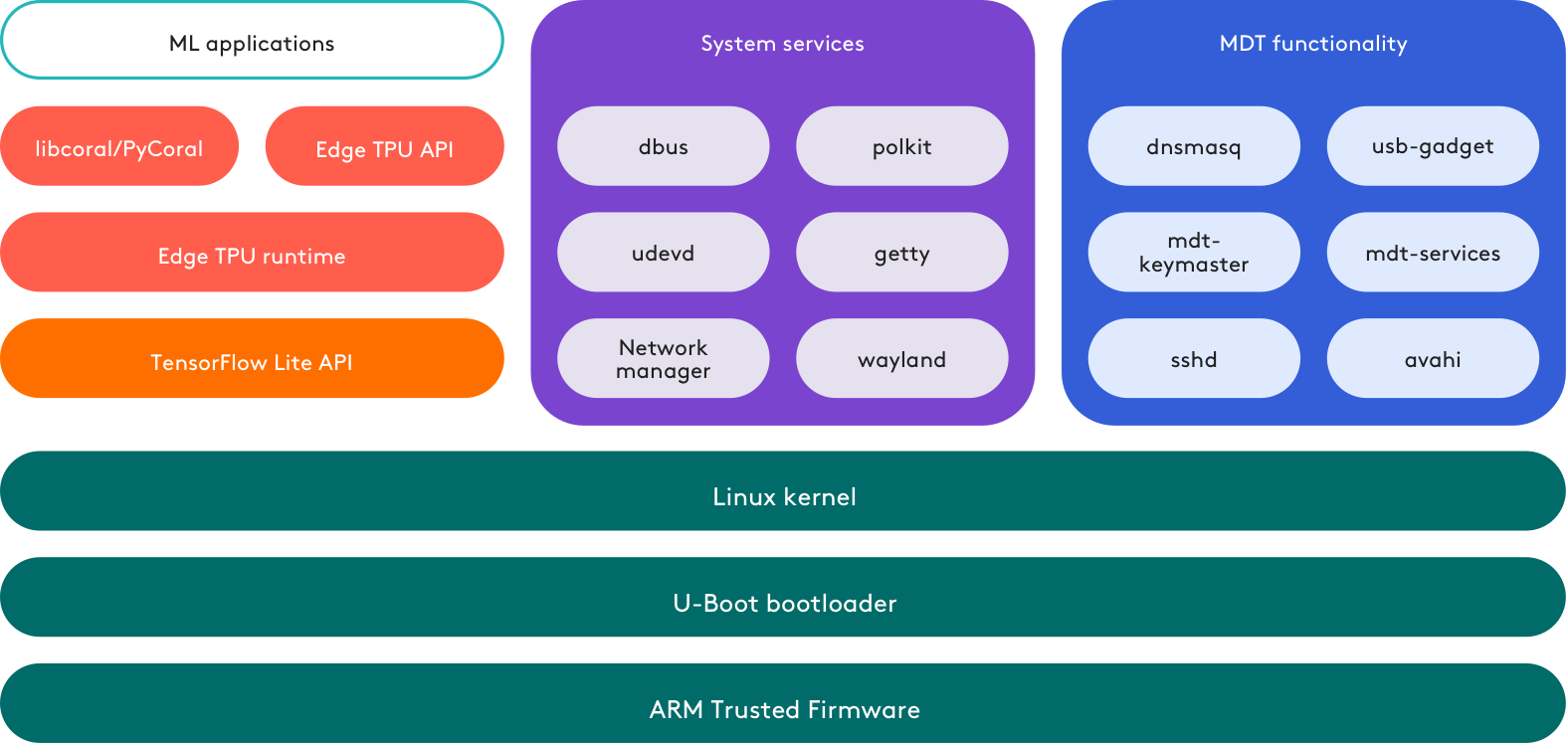
If you're instead using one of our accessory devices (the USB, Mini PCIe, or M.2 Accelerator), you don't need Mendel on your host system—you can use a Debian 6.0+ distribution or derivative.
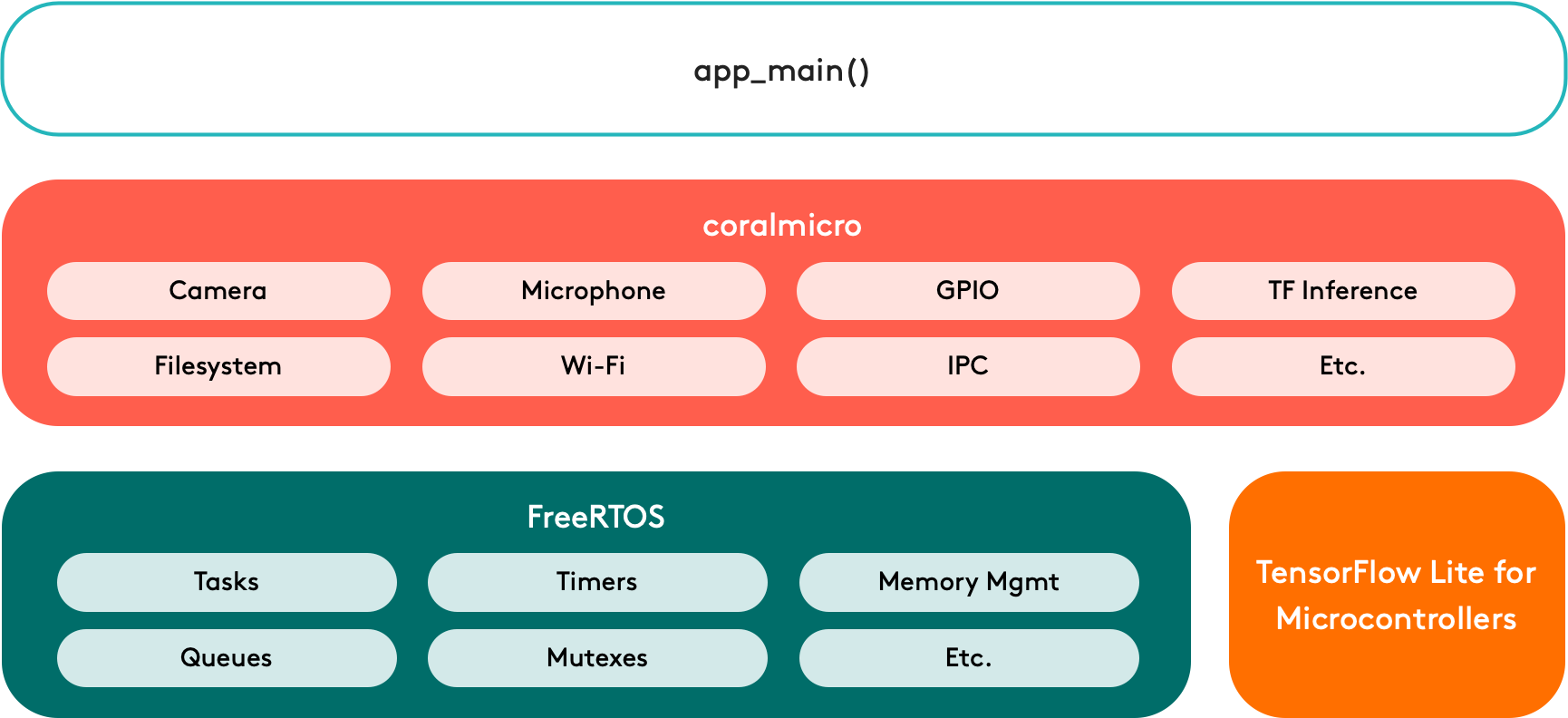
coralmicro
To simplify development for a microcontoller (MCU) board such as the Dev Board Micro, we built a real-time OS platform called coralmicro, based on FreeRTOS. It's a C++ programming environment with a CMake toolchain, but it also includes support for development with Arduino.
On top of FreeRTOS, we included APIs to use the Dev Board Micro's camera, microphone, and GPIOs, plus APIs for reading/writing files, creating RPC services, communicating across MCU cores, connecting to Wi-Fi (requires the Wireless Add-on board), and more. Of course, it also includes TensorFlow Lite for Microcontrollers to execute ML models on either the MCU or with acceleration on the Edge TPU.
Just like Mendel, coralmicro is completely open sourced.
Simultaneous inferencing
For applications that run multiple models, you can execute your models concurrently on a single Edge TPU by co-compiling the models so they share the Edge TPU scratchpad memory. Or, if you have multiple Edge TPUs in your system, you can increase performance by assigning each model to a specific Edge TPU and run them in parallel.
Learn more about running multiple models.
Model pipelining
For applications that require very fast throughput or large models, pipelining your model allows you to execute different segments of the same model on different Edge TPUs. This can improve throughput for high-speed applications and can reduce total latency for large models that otherwise cannot fit into the cache of a single Edge TPU.
Learn more about pipelining a model with multiple Edge TPUs.
On-device training
Although the Edge TPU is primarily intended for inferencing, you can also use it to accelerate transfer-learning with a pre-trained model. To simplify this process, we've created a Python API that executes the backbone of your model on the Edge TPU during training, and then calculates and saves new weight parameters for the final layer.
Learn more about on-device retraining.
Open source projects
As a company, we believe open source is good for everyone. Open and freely available code enables collaboration and advancement for all technology. So whenever we can, we open source our Coral software components.
You can find links to our open source projects on our software downloads page.
Getting started
Read more about each of our Coral products, or connect your device and run a model by following the setup guide for your device.