Build Coral for your platform
The setup guide for each Coral device shows you how to install the required software and run an inference on the Edge TPU. However, our pre-built software components are not compatible with all platform variants. If your host platform is not listed as one of our supported platforms (see the "requirements" in the product datasheet), you'll need to build the required components yourself (either natively or in a Docker/cross-compilation environment).
Building these components might be necessary if your system matches some of the requirements for our pre-build components (such as the Python version) but not others (such as the Debian version). Other examples of when it makes sense to build on your own include if you want to use a specific TensorFlow version or run on a Linux system that's not Debian-based. We can't possibly build for every scenario, and in some situations it's easier for you to build the libraries and APIs yourself instead of trying to change your system to match the platforms that we support.
This document describes how to build everything you need to run the Edge TPU as well as how to integrate and test the components.
Required components
You need the following software components to run inference on the Edge TPU:
- Edge TPU Runtime (libedgetpu): A shared library (libedgetpu.so.1) required to communicate with the Edge TPU from the TensorFlow Lite C++ API. (Also required if you're using Python.)
- TF Lite Runtime (tflite_runtime): A minimal version of the TensorFlow Lite Python API, required to run inferences in Python.
- PCIe Driver (gasket-dkms): Required for PCIe devices only, this package uses DKMS to install the Edge TPU driver.
And we recommend you write your application with one of the following API libraries:
- libcoral API: A C++ library that simplifies your code for running inference with TF Lite, and provides APIs for on-device transfer-learning and model pipelining with multiple Edge TPUs. (You can run inference in C/C++ without this library, using only the TensorFlow Lite and libedgetpu APIs.)
- PyCoral API: A Python library with the same functionality as libcoral. (You can run inference in Python without this library, using only the tflite_runtime API.)
Normally, you can install the pre-built version of these components (except libcoral) by following our device setup guides or downloading them from our downloads page. But to build them for your own platform, you'll need to follow the steps in the following sections.
Before you begin
There are a few things you need to decide on and verify before beginning this process:
- A TensorFlow Commit: The Edge TPU runtime, TF Lite runtime, and Edge TPU Python library must be built based on the same version of TensorFlow. Any arbitrary commit can work but we recommend using one of the TF Release Tags.
- Build natively or cross-compile: While native compilation will ensure that everything works as expected, cross-compilation can enable faster building on a workstation before deployment to devices. The directions for each will vary based on how you plan to build.
- For PCIe devices, verify your system supports MSI-X: While we can overcome many incompatibility issues by building, MSI-X is required by the Edge TPU silicon. Without it, there is no way to receive interrupts (and thus no way to know when operations complete).
Build the Edge TPU runtime (libedgetpu)
To install our pre-build Edge TPU runtime, you can run sudo apt install
libedgetpu1-std (or libedgetpu1-max in the case of maximum frequency for
USB). That package contains the shared library (libedgetpu.so.1), and you can then
dynamically link your project with
libedgetpu.
To build it yourself, first clone our libedgetpu repo.
git clone https://github.com/google-coral/libedgetpuNext, configure the bazel workspace to use the TensorFlow commit you have in
mind. For example, if you want to use TF v2.3.0 - as of this writing that tag
corresponds to commit b36436b087bd8e8701ef51718179037cccdfc26e (determined from
TF Release Tags). So insert
that as the TENSORFLOW_COMMIT value in the workspace.bzl file.
A checksum is also required for the TF package that you'll download. You could curl the object and compute this, or simply leave it for now, let it fail, and wait for the correct value to be reported.
If you're building natively, just run the Makefile:
makeIf you want to cross compile or use a known-good Docker container (which allows compilation of multiple CPU architectures), you can follow the libedgetpu README.
In any scenario, the output will be found in the out folder, as shown here:
├── direct
│ └── k8
│ ├── libedgetpu.so.1 -> libedgetpu.so.1.0
│ └── libedgetpu.so.1.0
└── throttled
└── k8
├── libedgetpu.so.1 -> libedgetpu.so.1.0
└── libedgetpu.so.1.0The library files in direct correspond to libedgetpu1-max (max frequency)
and those in throttled correspond to libedgetpu1-std (reduced frequency).
The frequency behavior only applies to USB devices; for PCIe devices, you can
use either library and the frequency is managed with
dynamic frequency scaling.
To deploy the library, copy this into your /usr/lib/. This exact location may
vary by system, but commonly you can move it as follows (for a x86_64 system):
sudo cp out/direct/k8/* /usr/lib/x86_64-linux-gnu/
sudo ldconfigFor usage information, see how to use the TF Lite Interpreter with libedgetpu.
Build the TF Lite runtime (tflite_runtime)
To install our pre-built TF Lite runtime (tflite_runtime), you can get it from Pip as per the
Python TF Lite quickstart.
To build it yourself, you first need to checkout the TensorFlow repo:
git clone https://github.com/tensorflow/tensorflow.git
cd tensorflow
git checkout <TF Commit ID you decided on above>Remember that you must checkout the same TensorFlow version that you used for
the TENSORFLOW_COMMIT value when
building the Edge TPU runtime.
The instructions that follow are the latest as of this publishing (and
simplified). For a more thorough procedure and the latest documentation, you
should see the
build instructions in the TensorFlow repo.
In that documentation, you'll see both build_pip_package.sh and
build_pip_package_with_bazel.sh. While both work, we recommend the Bazel
option (it doesn't require additional host dependencies) as follows.
To build natively (for TF versions > 2.2):
tensorflow/lite/tools/pip_package/build_pip_package_with_bazel.shTo build natively (for TF versions < 2.2):
tensorflow/lite/tools/pip_package/build_pip.shTo cross-compile, see the steps at the build instructions in the TensorFlow repo.
To deploy, simply use pip to install (for version 2.4.0 in this case):
python3 -m pip install \
tensorflow/lite/tools/pip_package/gen/tflite_pip/python3/dist/tflite_runtime-2.4.0-py3-none-any.whlBuild the libcoral API
If you want to use the libcoral C++ API for development, you need to compile the library with your project using Bazel. For details, see the README in the libcoral repo.
Build the PyCoral API
The PyCoral API uses pybind to provide a Python API based on libcoral.
Note: This build requires Docker. See the Docker install guide.
The following commands show how you can get the code, build it, and install it. Beware that the
pycoral repo includes both libcoral and libedgetpu as submodules, and by default, the pycoral
WORKSPACE file defines the TENSORFLOW_COMMIT that is passed through to those libraries to
ensure they're using the same TensorFlow version.
git clone --recurse-submodules https://github.com/google-coral/pycoral --depth 1
cd pycoral
# By default, this builds all supported versions, so takes a long time.
# You should edit the build script to build only what you need.
sudo bash scripts/build.sh
make wheel
python3 -m pip install $(ls dist/*.whl)For usage information, see Run inference on the Edge TPU with Python.
Build the Edge TPU Python API
The Edge TPU Python API has a swig-based native layer so an
architecture-specific build is required. Using build_swig.sh provides support
for ARM64, ARMv7, and x86_64 for Python 3.5, 3.6, 3.7, and 3.8 (note that only
one wheel is generated supporting all of these).
Before you build the library, edit the WORKSPACE file at the root of the repository
to specify the TENSORFLOW_COMMIT, using the same value you used when
building the Edge TPU runtime.
To build it yourself, follow the steps in the edgetpu repo.
Build the PCIe Driver (gasket-dkms)
This is required only for PCIe devices such as the Accelerator Module and Mini PCIe or M.2 Accelerator cards.
To get our pre-build PCie driver, you can get it from a Debian package (gasket-dkms), as per the getting started guide. This package requires the appropriate kernel headers for your device, in which case it will use DKMS to install the module into your kernel when the package is installed.
If you don't have a Debian system or are encountering issues with the DKMS install, you can add the source directly to your kernel tree. The source directory should be copied into your kernel. For example, here's how to add it to your kernel:
wget https://coral.googlesource.com/linux-imx/+archive/refs/heads/dkms/drivers/staging/gasket.tar.gz gasket.tar.gz
mkdir <kernel location>/drivers/staging/gasket
tar -xf gasket.tar.gz -C <kernel location>/drivers/staging/gasketYou also need to add the config CONFIG_STAGING_APEX_DRIVER to your kernel
config to ensure this is built. For example (building into the kernel, set to
"m" for a module):
echo "CONFIG_STAGING_APEX_DRIVER=y" >> defconfigThen build your kernel as you usually would and deploy it to your device.
Test everything
After you'd deployed all the necessary components as shown above, you can test it by running this classification demo on your device:
mkdir coral && cd coral
git clone https://github.com/google-coral/tflite.git
cd tflite/python/examples/classification
bash install_requirements.sh
python3 classify_image.py \
--model models/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \
--labels models/inat_bird_labels.txt \
--input images/parrot.jpgYou should see a result like this (note the speed will vary based on the interface used):
INFO: Initialized TensorFlow Lite runtime.
----INFERENCE TIME----
Note: The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory.
11.8ms
3.0ms
2.8ms
2.9ms
2.9ms
-------RESULTS--------
Ara macao (Scarlet Macaw): 0.76562Troubleshooting
The following are some common errors you might encounter.
Failed to load delegate from libedgetpu.so.1
Failing to load the delegate is a very general error that can indicate a few issues such as the following.
The runtime isn't installed: To verify your runtime is installed you can use Python's ctypes, which is what loads the library.
python3 -c "from ctypes.util import find_library; print(find_library(\"edgetpu\"))"The output should yield libedgetpu.so.1. If it doesn't, the runtime isn't
installed (see Edge TPU Runtime (libedgetpu)).
The Edge TPU isn't available: This error will also manifest if the device can't be found.
For USB:
lsusb -d 1a6e:089aThe output should show 1a6e:089a Global Unichip Corp. If not, the device isn't
available over USB. Check the connection and your dmesg output to see if there
was a kernel error preventing communication.
For PCIe:
ls /dev | grep apexThe output should yield (assuming only one TPU) /dev/apex_0. If there is no
Apex device, check your dmesg output and see PCIe errors.
No module named 'tflite_runtime'
This error indicates that the TF Lite runtime isn't installed. Follow the instructions in TF Lite Runtime for building and installing the TF Lite runtime.
Unsupported data type in custom op handler: (EdgeTpuDelegateForCustomOp) failed to prepare
After running a TF Lite model through the Edge TPU Compiler, everything that is mapped to the Edge TPU is placed in a single op (edgetpu-custom-op). This means that if the model fully runs on the Edge TPU, the entire model is in this operation and input/output:
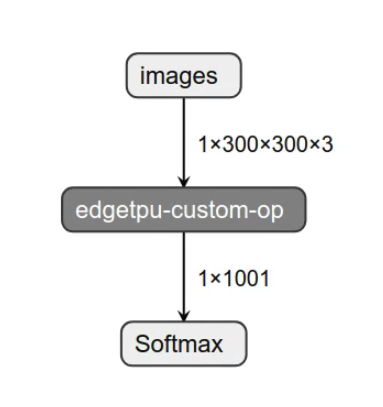
In order to run properly, this edgetpu-custom-op must be properly handled. So this error indicates that the delegate has issues running with the current setup. There is a mismatched version between one of the following:
- Edge TPU Runtime
- TF Lite Runtime
- (For C++) Edge TPU Runtime linked against when building
If building everything (as described in this document), the key is ensuring that each component was built using the same TensorFlow commit.
It is also possible that the model was compiled using a new Edge TPU Compiler but the runtimes are an older version (for example, using a TensorFlow commit that is for TensorFlow 1.15 but then using the latest Edge TPU compiler).
If you've confirmed that the built packages use the same TensorFlow commit, the next step is to try a model from coral.ai/models/. If these models don't work, you likely need to pick a more recent TensorFlow commit (keep in mind the compatibility layer can provide most 1.x API in TF 2.x). If the website models work but your model doesn't, please contact coral-support@google.com to help evaluate the compilation issues.
Is this content helpful?